画像生成AIを試してみた
昨今、AI(人工知能)は私たちの生活に大きな変化をもたらしています。
AI技術は急速に進化し、日常からビジネス、医療、エンターテインメントまで、
様々な分野で活用されている場面をよく見かけるようになりました。
今回は、そのようなAI技術の1つである、画像生成AIについてお話しします。
画像生成AIについてよく分からない、試しにAIで画像を生成してみたいという方に向けて、
概要から、実際にツールを使用してAIで画像を生成してみるところまでをご紹介いたします。
画像生成AIについて
画像生成AIの流れを簡単にご説明しますと、「こうゆう画像がほしい」と思ったイメージに合わせてワードを入力すると、入力したテキストに沿ったイメージ画像をAIが自動で生成してくれるといったシステムです。
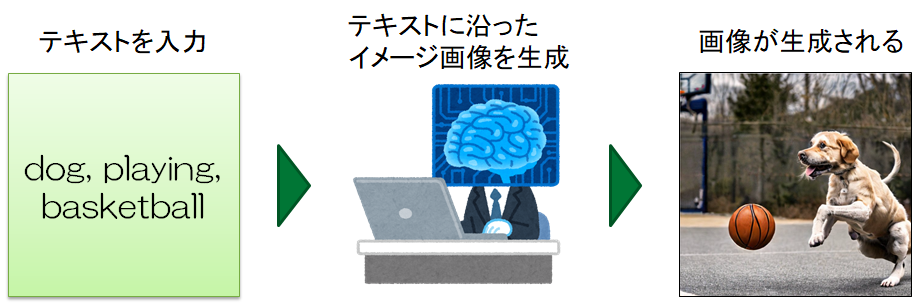
「dog, playing, basketball」のようにイメージに合うワードをカンマ区切りで繋げて入力します。
すると、実際に上記右の写真が生成されました。
メリット・デメリット
画像生成AIには沢山のメリットがありますが、デメリットもあります。
メリット
欲しい画像の特徴を伝えると、数秒でハイクオリティな画像が生成される
イラストやデザインを自分で作成しようと思うと時間がかかります。画像生成AIを使用すれば、「こんな画像が欲しい」と思ったら、そのイメージに合ったテキストを入力するだけで数秒~数十秒程度で画像ができてしまいます。
存在しないシチュエーションなど、ユニークな画像が生成できる
前述で「バスケットボールをしている犬」のように普段見られない光景だったり、シチュエーションを生み出すことができるのも魅力の1つです。
作業の効率化
資料作成やWebサイト制作など、画像が必要になるシチュエーションは多くあるでしょう。そういった際、欲しい画像をテキスト入力だけでパッと作れてしまえば、作業時間を大幅に短縮できます。
様々なタッチのデザイン生成が可能
画像生成AIはアニメ風だったり、写真風だったり、さらには背景など、様々なタッチの画像生成が可能なため、様々なパターンでアイデアを膨らませることができます。
デメリット
画像の品質が不安定
生成した画像の中には、ぼやけてしまったり、不自然だったりと必ずしも品質が一定ではありません。ですが、AI技術は急速に成長を進めているため、より進化していくことでしょう。
著作権の侵害問題
画像生成AIで特に注目されているのが、著作権の問題です。生成された画像が既存の著作権や知的財産権を侵害しないか注意する必要があります。今後、法整備がしっかり整うまで色々と問題が発生しそうですね。
日本語対応が少ない
画像生成AIサービスのほとんどは英語対応となっており、指示するワードを英語で入力する必要があります。日本語対応のサービスも存在はしておりますが、翻訳ツールを使うことも1つの手としてこの問題は回避できますね。
フェイク画像などの悪用
法整備が不完全なこともあり、AIで生成した画像を使用して悪用するケースが発生しています。特に災害の様子のフェイク画像が流出し、多くの人が勘違いしてしまうことが過去に起きています。よく見ると不自然な部分があり、フェイク画像だと判断されていますが、画像の精度も上がってきているため、ますます見分けがつかなくなってしまいます。自分でしっかり情報収集し、見分けられる力が必要になってきます。
活用方法
画像生成AIはどのような場面で活用されているのでしょうか。
独自のイラストが欲しくても、絵を描くことが苦手だったり、アイデアが浮かばなかったり、、、
そんな時にすぐにオリジナルの画像を生成してくれるのはとても魅力的です。
上記はほんの一部で、他にも様々な場面で活用されています。
趣味として楽しんだり、ビジネスの中で作業の効率化として活用したり、医療現場でも活用されているようで、今後さらに画像生成AIの注目が集まりますね。
実際に画像生成AIで画像を生成してみた
今回、以下の手順で画像生成AIを試してみました。
使用するツール
手順
①Paperspaceで仮想環境を作成する
②Stable Diffusion Web UIとモデルの追加
手順① Paperspaceで仮想環境を作成する
まず、Stable Diffusion Web UIで画像生成AIを使うために、2種類の方法があります。
1つはハイスペックなPCを用意すること、もう1つはクラウドサービスを利用することです。
前者の場合、特に重要なのが、画像処理を行うGPUのスペックとして、VRAM12GB以上が推奨されています。
今回は、誰でも実現できるよう、後者のクラウドサービスを利用してみました。
利用したクラウドサービスは、定額制で使い放題の「Paperspace」というものです。
まずは、上記ログイン画面からPaperspaceの登録をします。
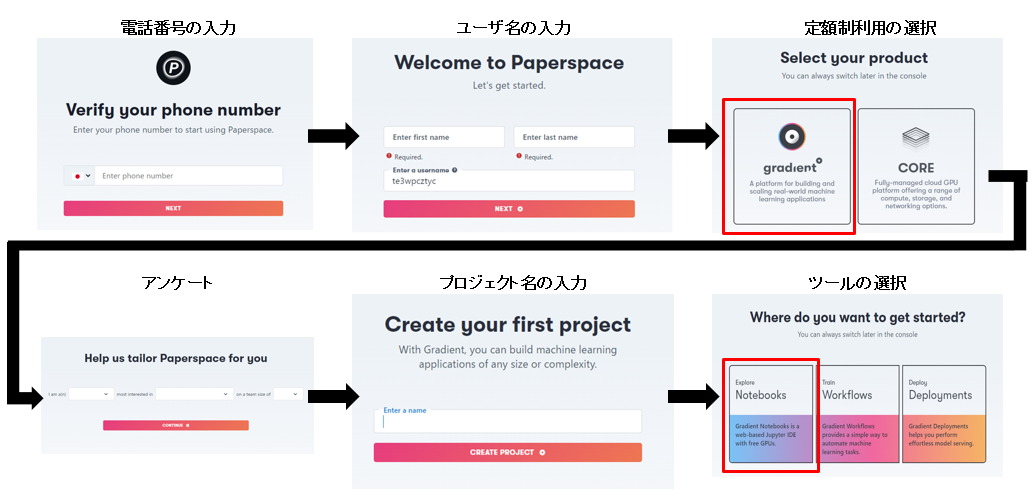
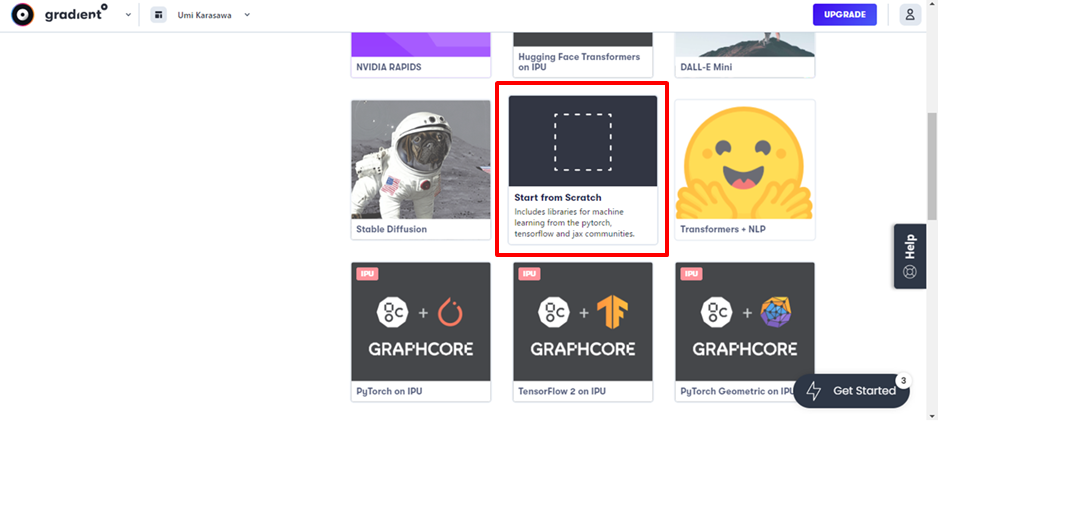
登録が完了したら、Notebooksを作成し、GPUをレンタルします。
「Start from Scratch」を選択し、
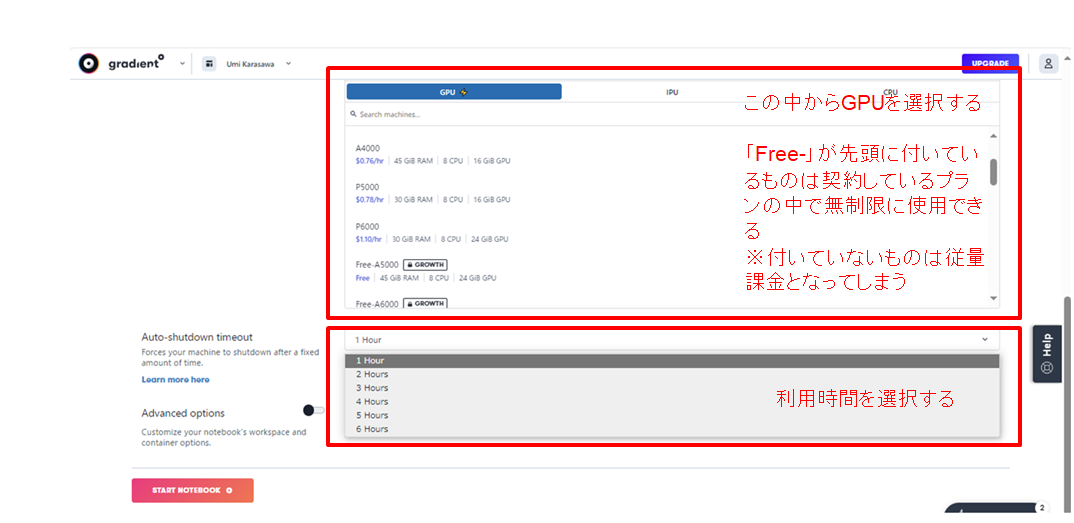
あとは、利用時間を選択できます。ここでいう利用時間は自動でシャットダウンされてしまう時間です。時間を過ぎてしまった場合は、再度借りなおせば、続けて使用できます。
手順② Stable Diffusion Web UIとモデルの追加
PaperspaceにStable Diffusion Web UIとモデルを追加していきます。
Github上にPaperspaceのテンプレートがあるのでダウンロードしてきます。
上記Githubからテンプレートをダウンロードし、Paperspaceにアップロードすると下記の画像のように、コマンドが4つに分類されています。それぞれ一番上にコメントで番号がふられているため、順番に実行していくと、Stable Diffusion Web UIとモデルの追加が完了します。

一番上の「#(3) WebUI起動」を実行すると、Stable Diffusion Web UIのパブリックのURLが表示されるため、クリックします。

試しに、「犬が走っている画像」⇒「dog,run」と入力し、Generateボタンを押下すると下記の図のような犬がこちらに向かって走ってくるような画像が生成されました!
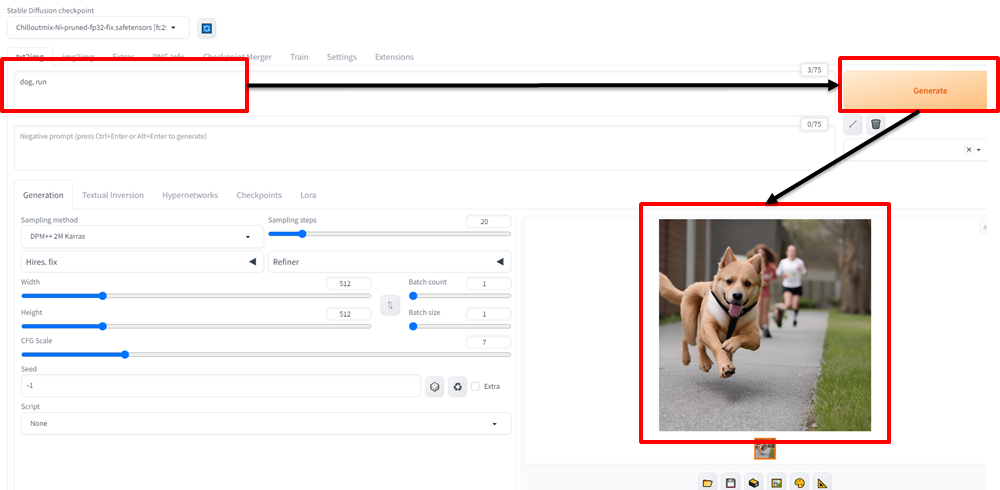
ちょこっとAIで画像生成してみたいという場合は無料で簡単に試すことができるサイトもあります。さらに幅広く、画像生成AIを無制限で使いたい、追加学習させてみたいなど、新たな可能性を広げたい場合に、高性能なPCを持っていないという方はぜひ参考にしてみてください。
まとめ
今回は、画像生成AIについてお話ししました。
まだまだ、豊富な設定項目だったり、モデルだったり、様々な機能が存在するため、そういった機能を駆使することで、生成画像の幅がもっと広がります。
本記事で少しでもご興味を持ってくださいましたら、ぜひ画像生成AIを試してみてください。